Ho un programma che ha bisogno di calcolare ripetutamente il percentile approssimativo (statistica dell'ordine) di un set di dati per rimuovere i valori anomali prima dell'ulteriore elaborazione. Attualmente sto facendo questo ordinando la matrice di valori e selezionando l'elemento appropriato; questo è fattibile, ma è un blip apprezzabile sui profili nonostante sia una parte piuttosto secondaria del programma.Algoritmo rapido per calcolare percentili per rimuovere i valori anomali
Maggiori informazioni:
- L'insieme di dati contiene dell'ordine di un massimo di 100000 numeri in virgola mobile, e assunto come "ragionevolmente" distribuito - c'è improbabile che siano duplicati, né enormi picchi di densità nei pressi di particolare valori; e se per qualche strana ragione la distribuzione è dispari, va bene che un'approssimazione sia meno accurata dato che i dati probabilmente sono incasinati e ulteriori elaborazioni discutibili. Tuttavia, i dati non sono necessariamente distribuiti uniformemente o normalmente; è molto improbabile che sia degenerato.
- Una soluzione approssimativa andrebbe bene, ma ho bisogno di capire come l' l'approssimazione introduce errore per assicurarsi che sia valido.
- Poiché lo scopo è rimuovere i valori anomali, sto calcolando due percentuali sugli stessi dati in ogni momento: ad es. uno al 95% e uno al 5%.
- L'app è in C# con bit di sollevamento pesante in C++; pseudocodice o una libreria preesistente in entrambi andrebbero bene.
- Un modo completamente diverso di rimuovere i valori anomali andrebbe bene, purché sia ragionevole.
- Aggiornamento: Sembra che stia cercando un approssimativo selection algorithm.
Anche se questo è tutto fatto in un ciclo, i dati sono (leggermente) diverso ogni volta, quindi non è facile da riutilizzare una datastructure come è stato fatto for this question.
implementato la soluzione
Usando l'algoritmo di selezione wikipedia come suggerito da Gronim ridotto questa parte del run-time di circa un fattore 20.
Dal momento che non riuscivo a trovare un'implementazione C#, ecco quello che ho si avvicinò. È più veloce anche per piccoli input rispetto a Array.Sort; e a 1000 elementi è 25 volte più veloce.
public static double QuickSelect(double[] list, int k) {
return QuickSelect(list, k, 0, list.Length);
}
public static double QuickSelect(double[] list, int k, int startI, int endI) {
while (true) {
// Assume startI <= k < endI
int pivotI = (startI + endI)/2; //arbitrary, but good if sorted
int splitI = partition(list, startI, endI, pivotI);
if (k < splitI)
endI = splitI;
else if (k > splitI)
startI = splitI + 1;
else //if (k == splitI)
return list[k];
}
//when this returns, all elements of list[i] <= list[k] iif i <= k
}
static int partition(double[] list, int startI, int endI, int pivotI) {
double pivotValue = list[pivotI];
list[pivotI] = list[startI];
list[startI] = pivotValue;
int storeI = startI + 1;//no need to store @ pivot item, it's good already.
//Invariant: startI < storeI <= endI
while (storeI < endI && list[storeI] <= pivotValue) ++storeI; //fast if sorted
//now storeI == endI || list[storeI] > pivotValue
//so elem @storeI is either irrelevant or too large.
for (int i = storeI + 1; i < endI; ++i)
if (list[i] <= pivotValue) {
list.swap_elems(i, storeI);
++storeI;
}
int newPivotI = storeI - 1;
list[startI] = list[newPivotI];
list[newPivotI] = pivotValue;
//now [startI, newPivotI] are <= to pivotValue && list[newPivotI] == pivotValue.
return newPivotI;
}
static void swap_elems(this double[] list, int i, int j) {
double tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
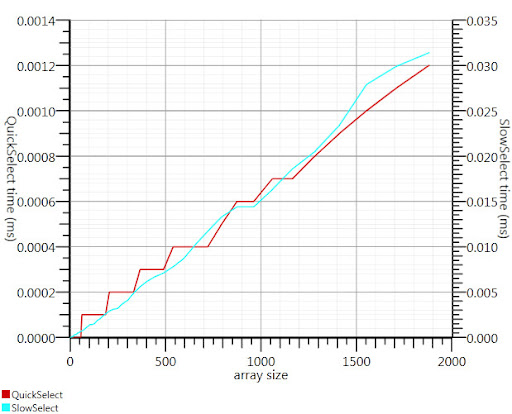
Grazie, Gronim, per me che punta nella direzione giusta!
Giusto, questo è quello che stavo cercando: un algoritmo di selezione! –