7
Ho una lista di testo in formato token (list_of_words) che sembra qualcosa di simile:Come rimuovere date da una lista in Python
list_of_words =
['08/20/2014',
'10:04:27',
'pm',
'complet',
'vendor',
'per',
'mfg/recommend',
'08/20/2014',
'10:04:27',
'pm',
'complet',
...]
e sto cercando per togliere tutte le istanze di date e orari da questa lista. Ho provato a utilizzare la funzione .remove(), senza alcun risultato. Ho provato a passare caratteri jolly, come "../../...." a un elenco di stopword con cui stavo ordinando, ma non ha funzionato. Alla fine ho provato a scrivere il seguente codice:
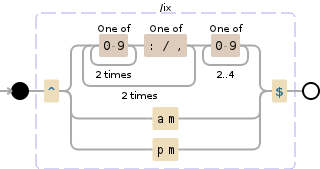
for line in list_of_words:
if re.search('[0-9]{2}/[09]{2}/[0-9]{4}',line):
list_of_words.remove(line)
ma anche questo non funziona. Come posso rimuovere tutto dal mio elenco formattato come una data o un'ora?

C'è un particolare formato di dati e/o tempo che vuoi rimuovere? – mng