Probabilmente hai bisogno di una rappresentazione dell'intervallo di confidenza per il tuo ctr stimato. Wilson score interval è una buona prova.
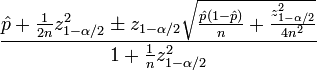
È necessario di seguito le statistiche per calcolare il punteggio di confidenza:
\hat p è il ctr constatato (frazione del #clicked vs #impressions)n è il numero totale di impressioniz α/2 è il quantile (1-α/2) dello standard né Distribuzione mal
Una semplice implementazione in pitone è mostrato sotto, uso z (1-α/2) = 1,96 corrispondente ad un intervallo di confidenza 95%. Ho allegato 3 risultati dei test alla fine del codice.
# clicks # impressions # conf interval
2 10 (0.07, 0.45)
20 100 (0.14, 0.27)
200 1000 (0.18, 0.22)
Ora è possibile impostare alcune soglie per utilizzare l'intervallo di confidenza calcolato.
from math import sqrt
def confidence(clicks, impressions):
n = impressions
if n == 0: return 0
z = 1.96 #1.96 -> 95% confidence
phat = float(clicks)/n
denorm = 1. + (z*z/n)
enum1 = phat + z*z/(2*n)
enum2 = z * sqrt(phat*(1-phat)/n + z*z/(4*n*n))
return (enum1-enum2)/denorm, (enum1+enum2)/denorm
def wilson(clicks, impressions):
if impressions == 0:
return 0
else:
return confidence(clicks, impressions)
if __name__ == '__main__':
print wilson(2,10)
print wilson(20,100)
print wilson(200,1000)
"""
--------------------
results:
(0.07048879557839793, 0.4518041980521754)
(0.14384999046998084, 0.27112660859398174)
(0.1805388068716823, 0.22099327100894336)
"""
{kind=link}
{kind=link}
Grazie per la risposta. Ma voglio sapere se esiste un metodo statistico normalizzato per le impressioni, non la confidenza per il ctr stimato. Ad esempio, questo metodo potrebbe essere simile al seguente: # (clic) * 2/(# (impressioni) + avg (#impressioni)) – Tim
In realtà non sono sicuro di aver capito cosa vuoi e perché lo vuoi. Che ne dici di uno stimatore bayesiano? O qualcosa come il punteggio IMDB? http://en.wikipedia.org/wiki/Bayes_estimator – greeness
Non z = 1,6 corrisponde al 90% di confidenza? Aiuto di Google: https://www.google.ru/search?q=z+values+confidence, article for dummies :-): http://www.dummies.com/how-to/content/finding-appropriate- zvalues-for-given-confidence-l.html – skaurus