35
Sto cercando di capire come calcolare la covarianza con la funzione Python Numpy cov. Quando passo a due matrici monodimensionali, ottengo una matrice 2x2 di risultati. Non so cosa fare con quello. Non sono bravo in statistica, ma credo che la covarianza in una situazione del genere dovrebbe essere un numero unico. This è quello che sto cercando. Ho scritto il mio:Calcolo della covarianza con Python e Numpy
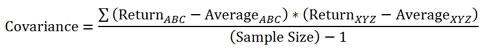{kind=link}
def cov(a, b):
if len(a) != len(b):
return
a_mean = np.mean(a)
b_mean = np.mean(b)
sum = 0
for i in range(0, len(a)):
sum += ((a[i] - a_mean) * (b[i] - b_mean))
return sum/(len(a)-1)
che funziona, ma immagino che la versione Numpy è molto più efficiente, se riuscivo a capire come usarlo.
Qualcuno sa come eseguire la funzione Numpy cov come quella che ho scritto?
Grazie,
Dave
osservazione Minore, ma si potrebbe trarre vantaggio da numpy per calcolare la somma: 'sum = ((a - a_mean) * (b - b-mean)). Sum()' – PlasmaBinturong