6
Ho intenzione di fare un po 'di rispolverare la mia conoscenza delle statistiche. Un'area in cui sembra che le statistiche sarebbero utili è nel codice di profilazione. Dico questo perché sembra che la profilazione implichi quasi sempre il tentativo di estrarre alcune informazioni da una grande quantità di dati.Quali concetti statistici sono utili per la profilazione?
Esistono argomenti in statistica che potrei rispolverare per ottenere una migliore comprensione dell'output del profiler? Punti bonus se puoi indicarmi un libro o un'altra risorsa che mi aiuterà a capire meglio questi argomenti.
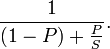
Questo è davvero alla fine come lo faccio, e probabilmente hai ragione. Tuttavia, mi piacerebbe saperne di più sulle statistiche, e questo sembra essere un buon posto per cercare di renderlo pratico. –
++ Neil ha ragione, anche se per lo più guardo il livello della linea, non il livello della funzione. (E, Neil, spero che per "percentuale di tempo" tu volessi dire "tempo totale", non "tempo di auto", e spero che intendessi "tempo dell'orologio a muro", non solo CPU, perché il software diventa grande, spreco di tempo diventa sempre più a causa di chiamate di funzione non necessarie, e alcune di queste fanno I/O.) –