L'approccio forza bruta sarebbe quello di provare ad aggiungere le lettere a ciascun indice disponibile utilizzando una ricerca in profondità.
Quindi, a partire da 'a', ci sono due posti in cui è possibile aggiungere una nuova lettera. Di fronte o dietro la 'a', rappresentata da punti sotto.
.a.
Se si aggiunge una 't', ora ci sono tre posizioni.
.a.t.
Si può provare ad aggiungere tutte le 26 lettere per ogni posizione disponibile. Il dizionario in questo caso può essere un semplice hashtable. Se aggiungi una "z" nel mezzo, ottieni "azt" che non si troverà nella tabella delle hash, quindi non proseguirai lungo quel percorso nella ricerca.
Modifica: il grafico di Nick Johnson mi ha fatto incuriosire su quale sarebbe il grafico di tutti i percorsi massimali. Si tratta di un'immagine di grandi dimensioni (1,6 MB) qui:
http://www.michaelfogleman.com/static/images/word_graph.png
Edit: Ecco un'implementazione di Python. L'approccio forza bruta funziona in realtà in un tempo ragionevole (alcuni secondi, a seconda della lettera iniziale).
import heapq
letters = 'abcdefghijklmnopqrstuvwxyz'
def search(words, word, path):
path.append(word)
yield tuple(path)
for i in xrange(len(word)+1):
before, after = word[:i], word[i:]
for c in letters:
new_word = '%s%s%s' % (before, c, after)
if new_word in words:
for new_path in search(words, new_word, path):
yield new_path
path.pop()
def load(path):
result = set()
with open(path, 'r') as f:
for line in f:
word = line.lower().strip()
result.add(word)
return result
def find_top(paths, n):
gen = ((len(x), x) for x in paths)
return heapq.nlargest(n, gen)
if __name__ == '__main__':
words = load('TWL06.txt')
gen = search(words, 'b', [])
top = find_top(gen, 10)
for path in top:
print path
Naturalmente, ci sarà un sacco di legami nella risposta. Questo stamperà i primi risultati N, misurati in base alla lunghezza dell'ultima parola.
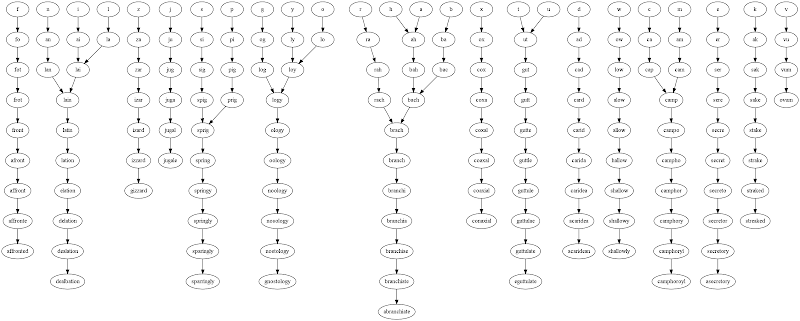
Uscita per lettera iniziale 'a', utilizzando il dizionario TWL06 Scrabble.
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampedes', 'stampeders'))
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampeder', 'stampeders'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangles', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangler', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangles', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangers', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangers', 'estrangers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'estranges', 'estrangers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranger', 'strangler', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranger', 'strangers', 'stranglers'))
e qui sono i risultati per ogni lettera iniziale. Naturalmente, viene fatta un'eccezione sul fatto che la singola lettera iniziale non deve essere nel dizionario. Solo una parola di 2 lettere che può essere formata con esso.
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampedes', 'stampeders'))
(9, ('b', 'bo', 'bos', 'bods', 'bodes', 'bodies', 'boodies', 'bloodies', 'bloodiest'))
(1, ('c',))
(10, ('d', 'od', 'cod', 'coed', 'coped', 'comped', 'compted', 'competed', 'completed', 'complected'))
(10, ('e', 're', 'rue', 'ruse', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(9, ('f', 'fe', 'foe', 'fore', 'forge', 'forges', 'forgoes', 'forgoers', 'foregoers'))
(10, ('g', 'ag', 'tag', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangles', 'stranglers'))
(9, ('h', 'sh', 'she', 'shes', 'ashes', 'sashes', 'slashes', 'splashes', 'splashers'))
(11, ('i', 'pi', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(7, ('j', 'jo', 'joy', 'joky', 'jokey', 'jockey', 'jockeys'))
(9, ('k', 'ki', 'kin', 'akin', 'takin', 'takins', 'takings', 'talkings', 'stalkings'))
(10, ('l', 'la', 'las', 'lass', 'lassi', 'lassis', 'lassies', 'glassies', 'glassines', 'glassiness'))
(10, ('m', 'ma', 'mas', 'mars', 'maras', 'madras', 'madrasa', 'madrassa', 'madrassas', 'madrassahs'))
(11, ('n', 'in', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(10, ('o', 'os', 'ose', 'rose', 'rouse', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(11, ('p', 'pi', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(3, ('q', 'qi', 'qis'))
(10, ('r', 're', 'rue', 'ruse', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(10, ('s', 'us', 'use', 'uses', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(10, ('t', 'ti', 'tin', 'ting', 'sting', 'sating', 'stating', 'estating', 'restating', 'restarting'))
(10, ('u', 'us', 'use', 'uses', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(1, ('v',))
(9, ('w', 'we', 'wae', 'wake', 'wakes', 'wackes', 'wackest', 'wackiest', 'whackiest'))
(8, ('x', 'ax', 'max', 'maxi', 'maxim', 'maxima', 'maximal', 'maximals'))
(8, ('y', 'ye', 'tye', 'stye', 'styed', 'stayed', 'strayed', 'estrayed'))
(8, ('z', 'za', 'zoa', 'zona', 'zonae', 'zonate', 'zonated', 'ozonated'))
{kind=link}
Interessante problema. Cosa hai provato finora e dove sei bloccato? –
Definisci "dizionario di parole". È un tavolo hash, un trie o cosa? Se è un trie, una semplice ricerca DF funzionerà. È un albero suffisso come suggeriscono i tag? – IVlad
Sembra un problema per i compiti a casa, scarsamente specificato. –