Sto scrivendo un algoritmo in OpenCL in cui avrei bisogno di ogni unità di lavoro per ricordare una buona parte dei dati, diciamo qualcosa tra uno long[70] e uno long[200] o giù di lì per kernel.memoria fisica su dispositivi AMD: locale vs privato
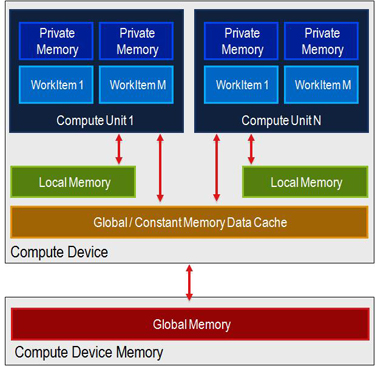
I dispositivi AMD recenti hanno 32 memoria KiB __local, che è (per la quantità data di dati per kernel) sufficiente per memorizzare le informazioni per 20-58 unità di lavoro. Tuttavia, da quello che ho capito dall'architettura (e in particolare da this drawing), ogni core dello shader ha anche una quantità dedicata di memoria privata. Tuttavia non riesco a trovare la sua dimensione.
{kind=link}
Qualcuno può dirmi come scoprire quanta memoria privata ha ogni kernel?
Sono particolarmente curioso dell'HD7970, dal momento che ho in programma di acquistarne presto alcuni.
Edit: Problema risolto, la risposta è here nell'Appendice D.
Non credo che la memoria privata sia dedicata per core: si associa al file di registro, che è per risorsa dell'unità di calcolo. Ogni elemento di lavoro ottiene i registri allocati dal file di registro dell'unità di calcolo, quanti sono necessari per determinare il numero di fronti d'onda in volo in un dato istante. – talonmies
Dal famoso disegno in tutto il mondo http://www.codeproject.com/KB/showcase/Memory-Spaces/image001.jpg Ho concluso che la memoria privata è fisicamente diversa dalla memoria __locale, no? – user1111929
Sì, sono fisicamente diversi. La memoria privata si associa al file di registro dell'unità di calcolo, la memoria locale per calcolare la memoria condivisa a livello di unità nella maggior parte dei dispositivi AMD moderni. Alcune prime GPU OpenCL compatibili non avevano memoria condivisa, e la memoria locale era solo SDRAM. Nessuno dei due è per core e quanto si utilizza per articolo di lavoro per gruppo privato e per gruppo di lavoro per effetti locali il numero di fronti d'onda simultanei in esecuzione per unità di calcolo. – talonmies